netobserv
Network Observability TCP Handshake Round Trip Time
By: Dushyant Behl, Julien Pinsonneau and Mohamed S. Mahmoud
In OpenShift Container Platform (OCP), ensuring efficient packet delivery is paramount for maintaining seamless communication between applications. However, challenges like network congestion, misconfigured systems, or hardware limitations can lead to slow connections, impacting overall performance. Round Trip Time (RTT), typically measured in milliseconds, plays a crucial role in monitoring network health and diagnosing issues.
Implementing Smooth Round-Trip Time (SRTT) with eBPF
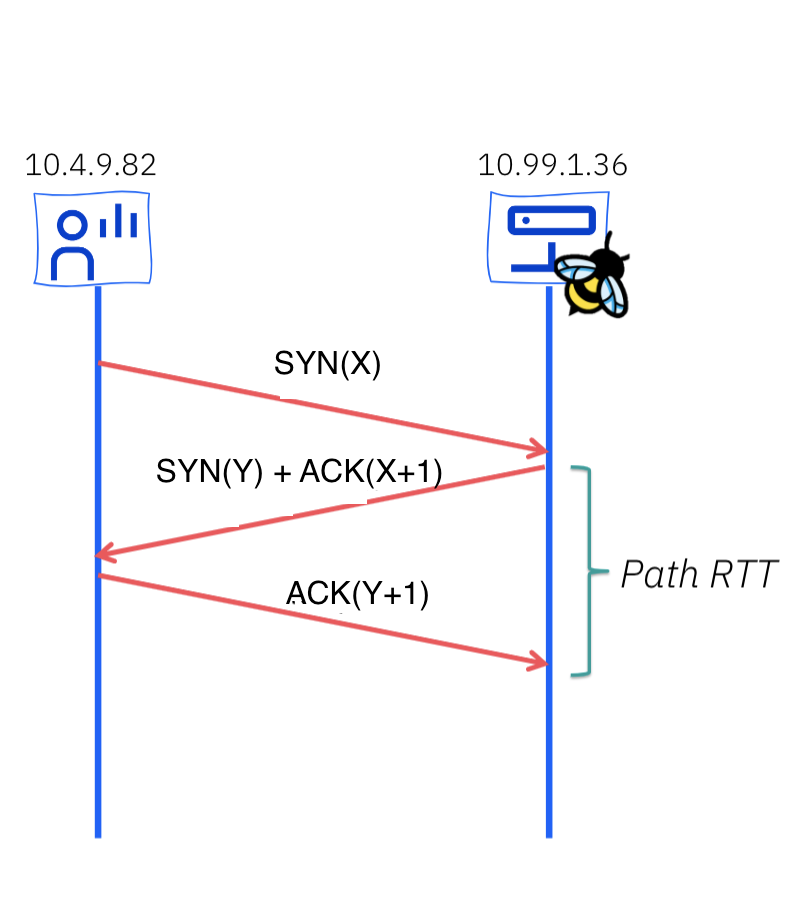
The RTT is the time it takes for a packet to travel from the sender to the receiver and back. In a network, RTT can vary due to factors like network congestion, varying route lengths, and other dynamic conditions. SRTT is introduced to provide a more consistent and less jittery representation of the RTT.
In TCP, RTT is a crucial metric.
Our implementation leverages eBPF to register to fentry eBPF hook
for tcp_rcv_established().
We extract the SRTT (smooth round-trip time) value from TCP sockets, correlating it
to existing flows and enriching them with RTT values in nanoseconds.
When a new Netobserv flow is created, and the RTT (Round-Trip Time) feature is enabled,
an initial RTT of 10usec is assigned.
This initial value for RTT may be considered quite low.
Upon triggering the eBPF (Extended Berkeley Packet Filter) socket, the flow RTT value is updated to reflect the maximum RTT value for that specific flow.
For more detailed explanation of smoothed RTT estimation, refer to Karn’s algorithm paper
Why using fentry eBPF hook
The eBPF fentry programs have lower overhead as they trigger
the hook before calling the kernel function of interest.
In our implementation:
- Register and link
fentryhook for kernel’stcp_rcv_established()
SEC("fentry/tcp_rcv_established")
int BPF_PROG(tcp_rcv_fentry, struct sock *sk, struct sk_buff *skb) {
if (sk == NULL || skb == NULL) {
return 0;
}
return calculate_flow_rtt_tcp(sk, skb);
}
-
Reconstruct the Netobserv flow key, including incoming interface Layer2, Layer3, and Layer4 info.
-
Match existing flows in the PerCPU hashmap flow table and enrich them with srtt info from TCP sockets. If multiple SRTT values exist for the same flow, we take the maximum value.
Currently, our approach calculates RTT only for the TCP packets so flows which are non-TCP do not show RTT information.
Potential Use Cases
Flow RTT capture from eBPF flow_monitor hookpoint can serve various purposes:
-
Network Monitoring: Gain insights into TCP handshakes, helping network administrators identify unusual patterns, potential bottlenecks, or performance issues.
-
Troubleshooting: Debug TCP-related issues by tracking latency and identifying misconfigurations.
How to Enable RTT
To enable this feature we need to create a FlowCollector object with the following fields enabled in eBPF config section as below:
apiVersion: flows.netobserv.io/v1beta2
kind: FlowCollector
metadata:
name: cluster
spec:
agent:
type: eBPF
ebpf:
features:
- FlowRTT
A Quick Tour in the UI
Once the FlowRTT feature is enabled, the OCP console plugin automatically adapts
to provide additional filter and show information across Netflow Traffic page views.
Open your OCP Console and move to
Administrator view -> Observe -> Network Traffic page as usual.
A new filter, Flow RTT is available in the common section:

The FlowRTT filter will allow you to capture any flow that has an RTT more than a specific time in nanoseconds.
For production users, filtering on the TCP protocol, Ingress direction,
and looking for FlowRTT values greater than 10,000,000 nanoseconds (10ms)
can help identify TCP flows with high latency.
This filtering approach allows users to focus on specific network flows that may
be experiencing significant delays.
By setting a threshold of 10ms, you can efficiently isolate and address potential
latency issues in your TCP traffic.
Overview
New graphs are introduced in the Advanced options -> Manage panels popup:
- Top X average TCP handshake Round Trip Time with overall (donut or lines)
- Bottom X minimum TCP handshake Round Trip Time with overall (donut or lines)
- Top X maximum TCP handshake Round Trip Time with overall (donut or lines)
- Top X 90th percentile TCP handshake Round Trip Time with overall (donut or lines)
- Top X 99th percentile TCP handshake Round Trip Time with overall (donut or lines)
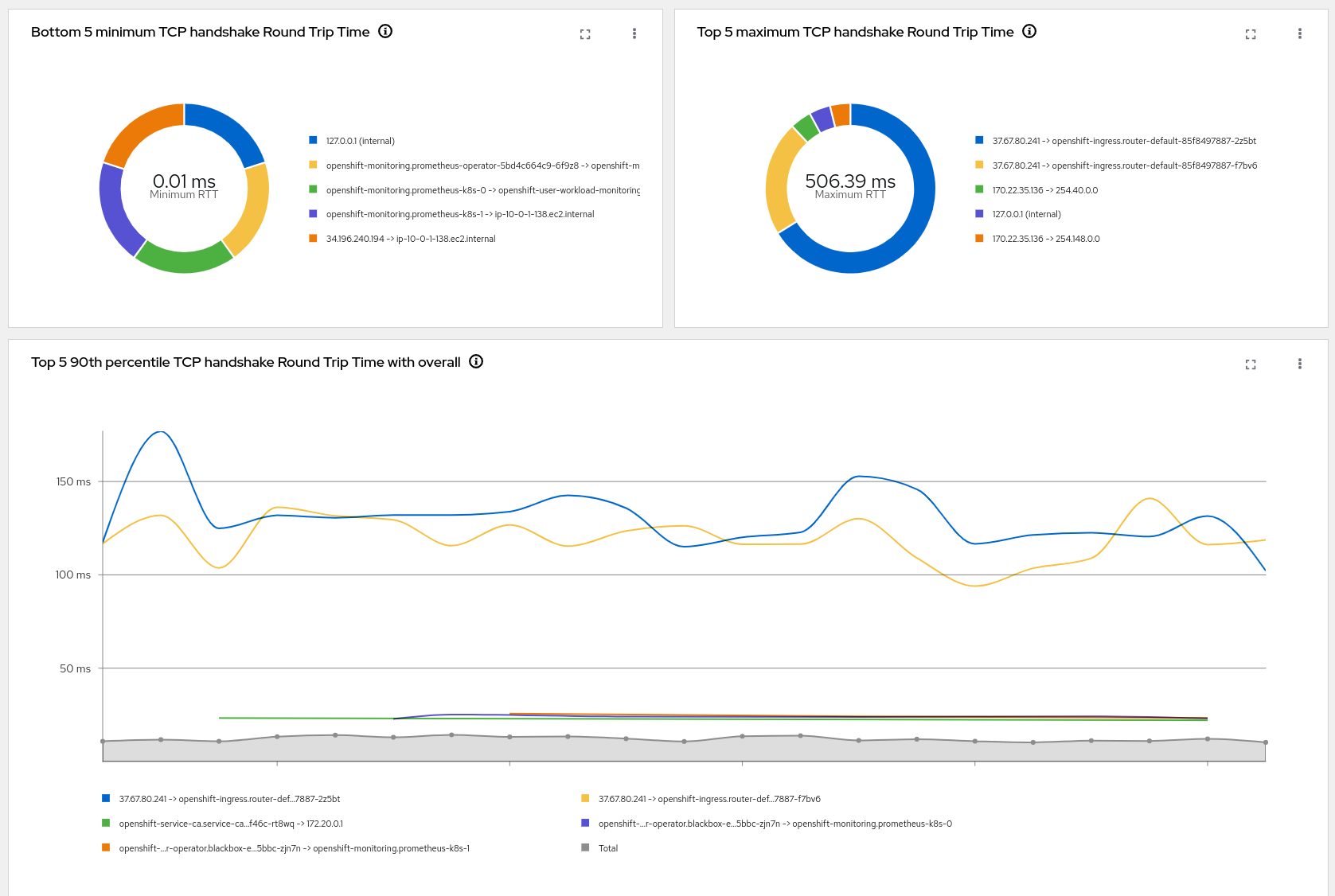
These two graphs can help you to identify the slowest TCP flows and their trends over time. Use the filters to drill down into specific pods, namespaces or nodes.
Traffic flows
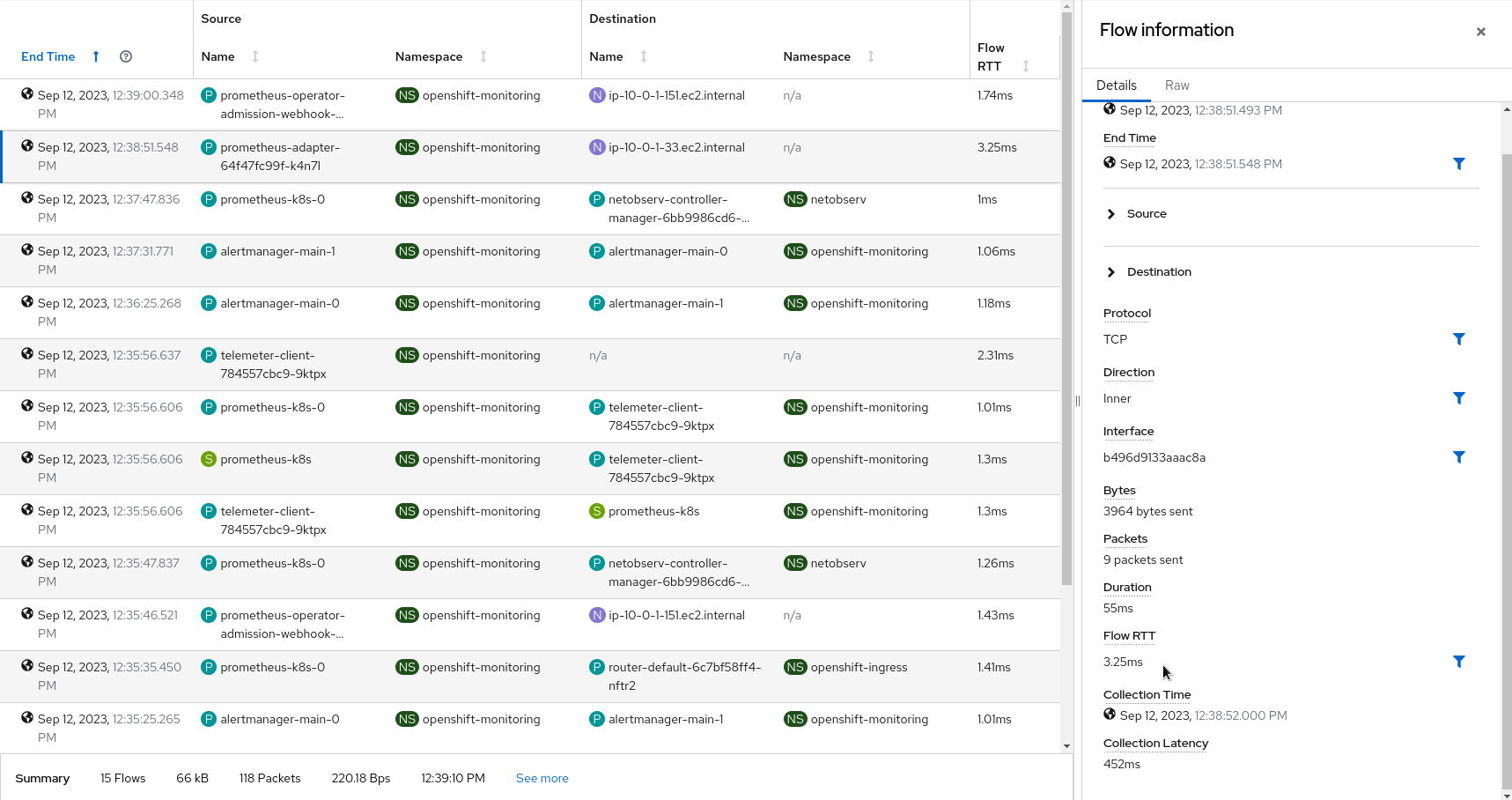
The table view shows the Flow RTT in both column and side panel.
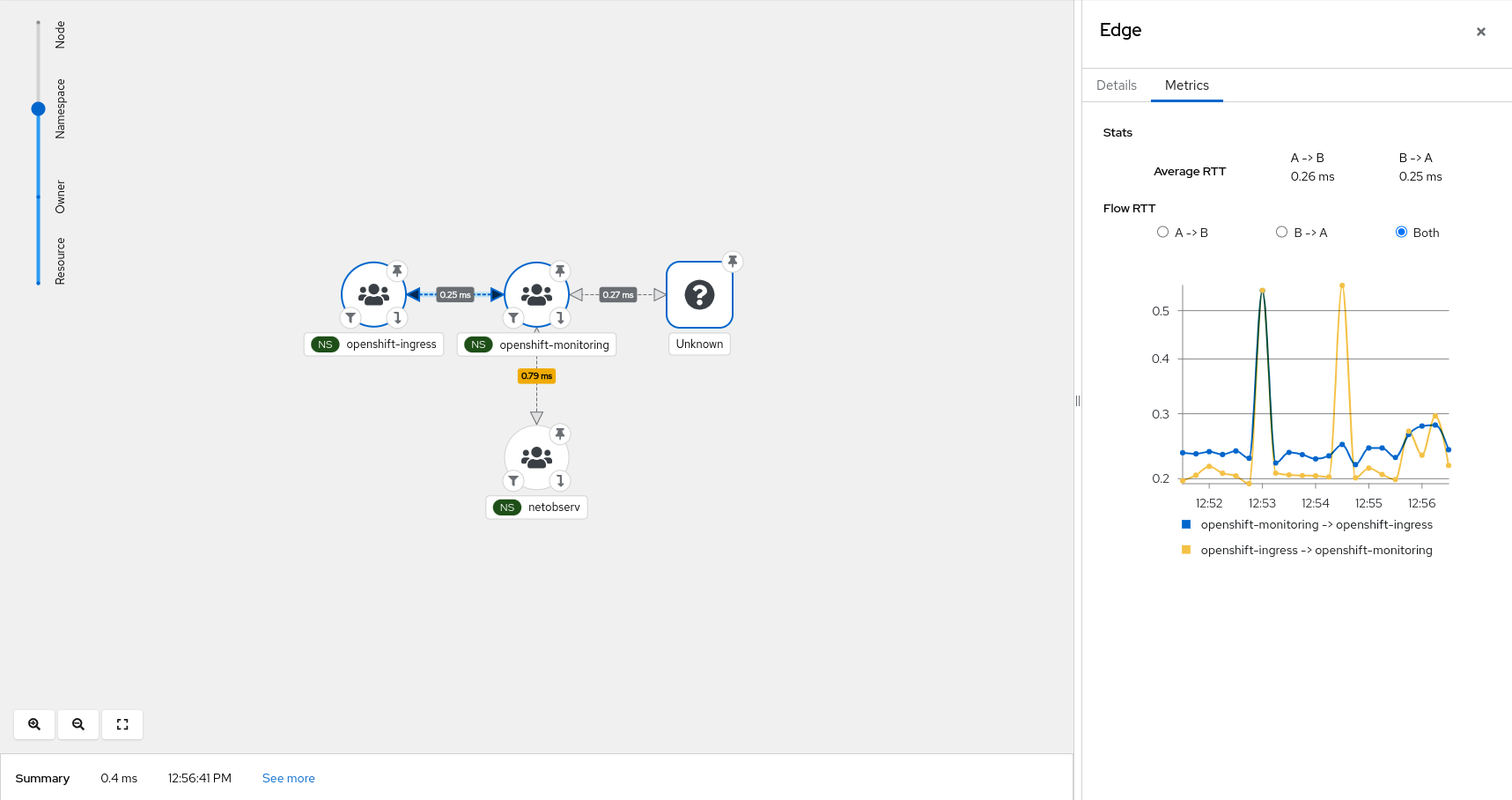
Topology
Last but not least, the topology view displays min / max / avg / p90 / p99 RTT
latency on edges.
Clicking on a node or an edge will allow you to see per direction metrics and
the related graph.
Future improvments
Here is a non exhaustive list of future improvements coming for a full featured Round Trip Time analysis:
- Latest RTT in topology view
- Prometheus metrics and alerting
Feedback
We hope you liked this article !
Netobserv is an OpenSource project available on github. Feel free to share your ideas, use cases or ask the community for help.